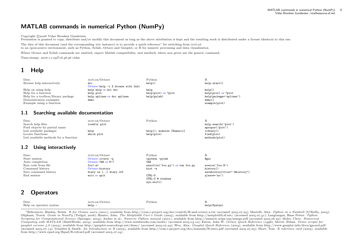
Python for Data Science Cheat Sheet - Data Wrangling in Pandas

The Python for Data Science Cheat Sheet - Data Wrangling in Pandas is a resource that provides a summary of useful commands and functions in the Pandas library for data wrangling purposes. It helps data scientists and analysts efficiently manipulate, clean, and transform data using Pandas.
FAQ
Q: What is Pandas?
A: Pandas is a Python library used for data manipulation and analysis.
Q: What is data wrangling?
A: Data wrangling refers to the process of cleaning and transforming data into a format that is suitable for analysis.
Q: How do I install Pandas?
A: You can install Pandas by using the pip package manager. Simply run 'pip install pandas' in your terminal or command prompt.
Q: What are some common data wrangling tasks in Pandas?
A: Some common data wrangling tasks include handling missing values, removing duplicates, merging datasets, and transforming data types.
Q: How do I handle missing values in Pandas?
A: You can handle missing values by using the 'dropna' method to remove rows or columns with missing values, or by using the 'fillna' method to replace missing values with a specified value.
Q: How do I remove duplicates in Pandas?
A: You can remove duplicates by using the 'drop_duplicates' method.
Q: How do I merge datasets in Pandas?
A: You can merge datasets by using the 'merge' function and specifying the common columns to merge on.
Q: How do I transform data types in Pandas?
A: You can transform data types by using the 'astype' method to convert a column to a different data type.
Q: What other functionalities does Pandas offer?
A: Pandas offers a wide range of functionalities for data manipulation, including filtering, sorting, grouping, and reshaping data.