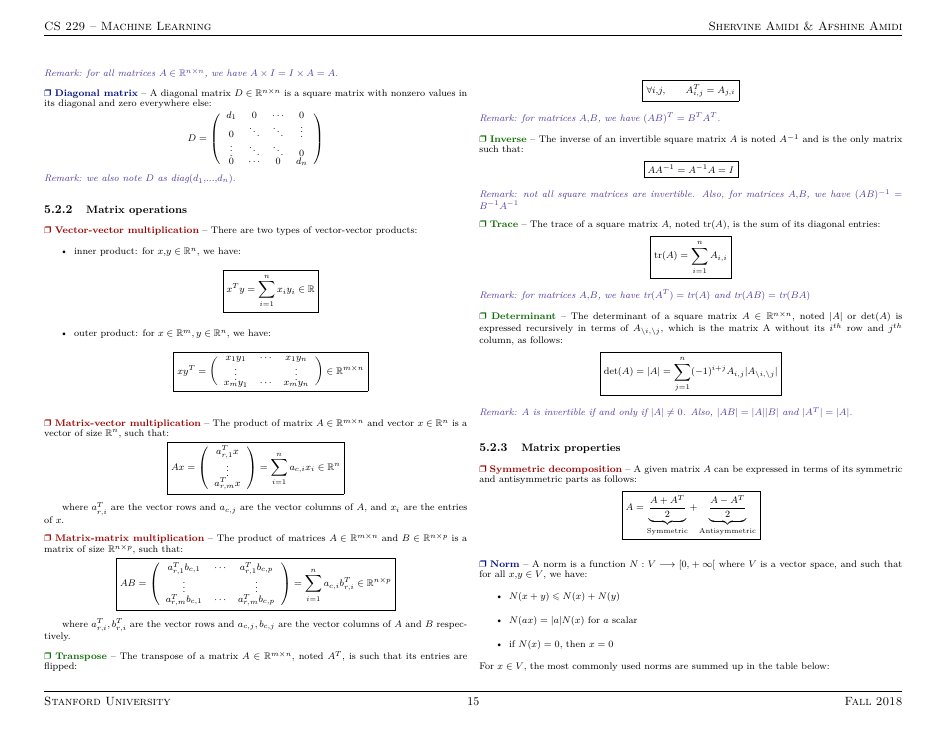
Machine Learning Cheat Sheet

The Machine Learning Cheat Sheet is a reference guide that provides a quick overview of key concepts, algorithms, and techniques in machine learning. It can be used as a handy resource for understanding and implementing machine learning models.
FAQ
Q: What is a cheat sheet?
A: A cheat sheet is a succinct overview of key information on a specific topic.
Q: What is machine learning?
A: Machine learning is a field of artificial intelligence that focuses on enabling computers to learn and make decisions without being explicitly programmed.
Q: What are some popular machine learning algorithms?
A: Some popular machine learning algorithms include decision trees, random forests, support vector machines, and neural networks.
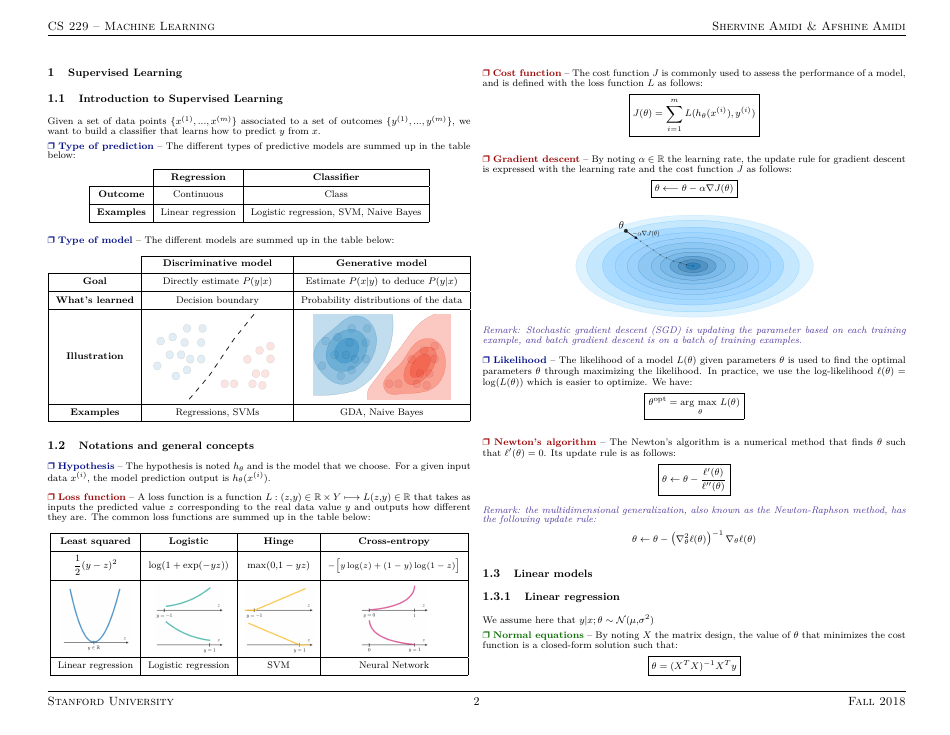
Q: What is supervised learning?
A: Supervised learning is a machine learning approach where the model is trained on labeled data to make predictions or classify new inputs.
Q: What is unsupervised learning?
A: Unsupervised learning is a machine learning approach where the model learns patterns and relationships in unlabeled data without any predefined outputs.
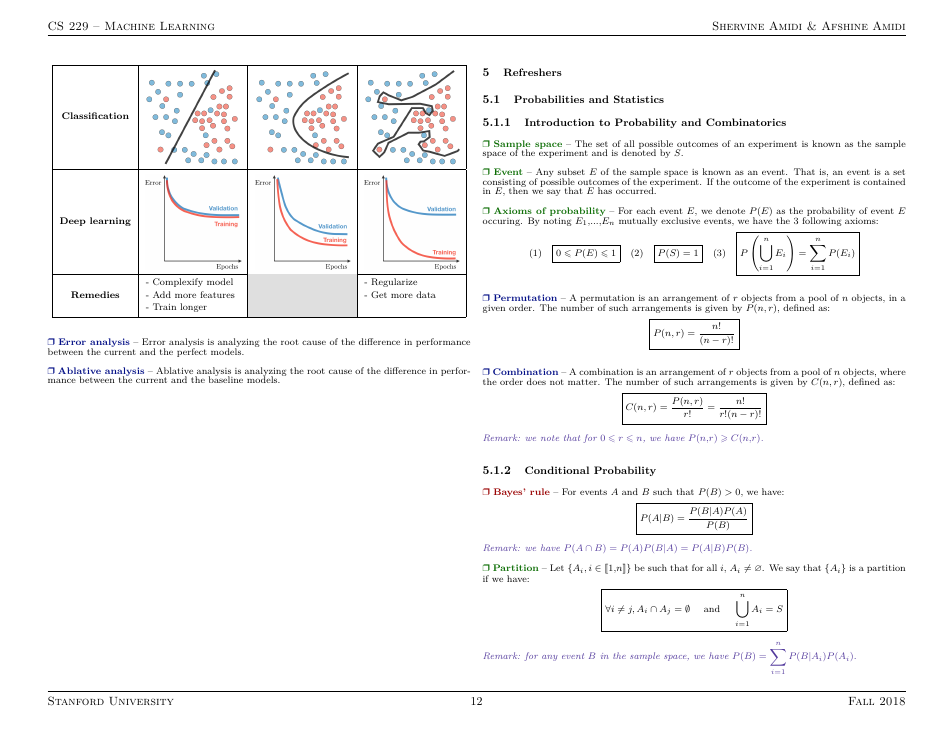
Q: What is the difference between classification and regression in machine learning?
A: Classification is a type of machine learning task that aims to categorize inputs into predefined classes, while regression predicts continuous numerical values.
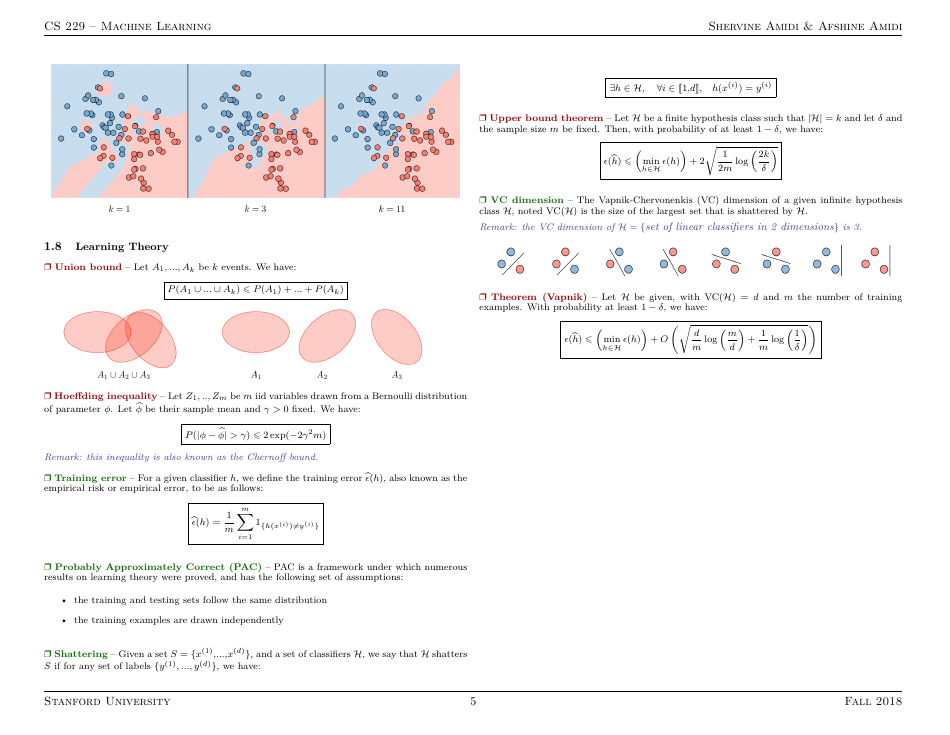
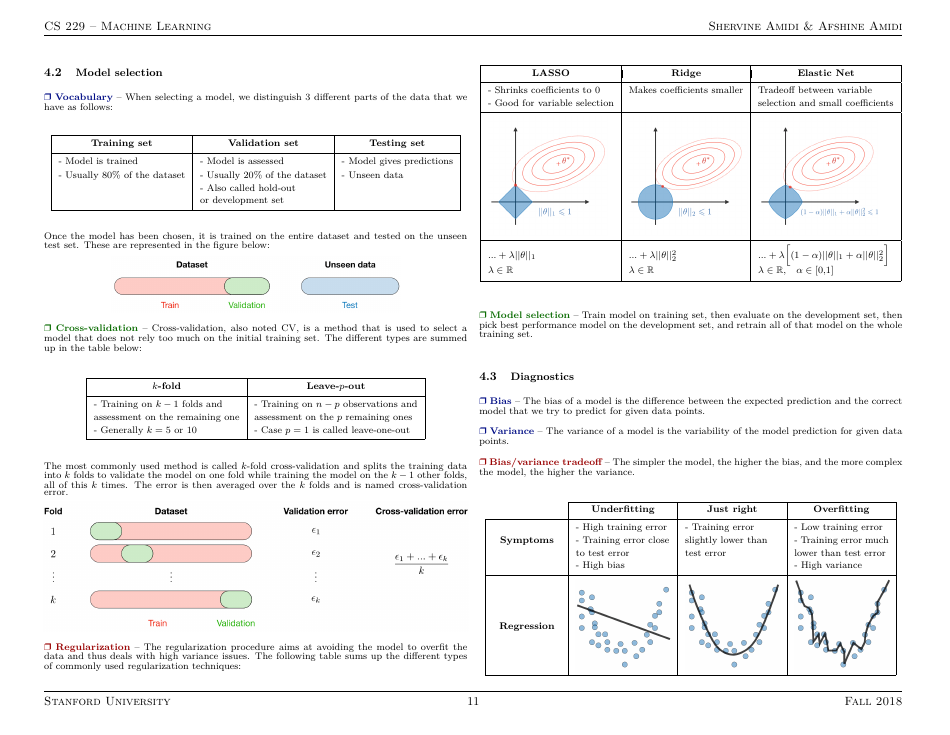
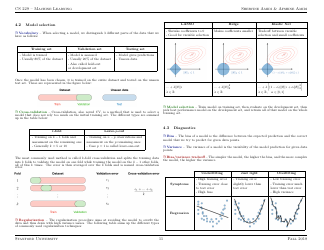
Q: What is overfitting in machine learning?
A: Overfitting occurs when a machine learning model performs well on the training data but poorly on unseen test data due to memorizing noise or irrelevant patterns.
Q: What is feature engineering?
A: Feature engineering is the process of transforming raw data into a format that is more suitable for machine learning algorithms, often involving feature selection and extraction.
Q: What is the difference between supervised and unsupervised learning?
A: Supervised learning uses labeled data to make predictions, while unsupervised learning learns patterns in unlabeled data without predetermined outputs.
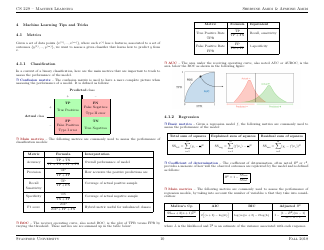
Q: What is a confusion matrix?
A: A confusion matrix is a table that summarizes the performance of a classification model by showing the counts of true positive, true negative, false positive, and false negative predictions.
Download Machine Learning Cheat Sheet

1
2

3

4
5

6

7

8
9
10
11

12

13

14
15

16