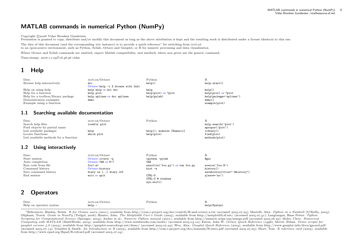
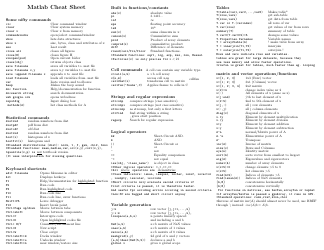
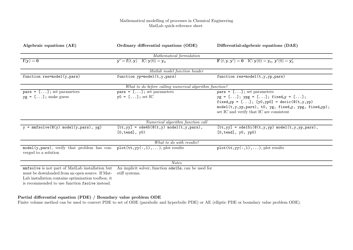
Python Cheat Sheet - Apache Spark

The Python Cheat Sheet - Apache Spark is a document that provides a quick reference guide for using the Python programming language with Apache Spark, a powerful big data processing framework. It offers a summary of important concepts, syntax, and functions to help users navigate and utilize Apache Spark more efficiently in Python coding.
FAQ
Q: What is Apache Spark?
A: Apache Spark is an open-source data processing framework that is designed for big data processing and analytics.
Q: What are the key features of Apache Spark?
A: Key features of Apache Spark include in-memory processing, fault-tolerance, support for various data sources, and support for multiple languages like Python, Scala, and Java.
Q: Why is Apache Spark popular?
A: Apache Spark is popular because it provides fast and scalable data processing capabilities, supports a wide range of data sources and tools, and has a strong and active community.
Q: What is the difference between Apache Spark and Hadoop?
A: Apache Spark is a data processing framework, while Hadoop is a distributed storage and processing framework. Spark can be used with or without Hadoop.
Q: How does Apache Spark handle big data?
A: Apache Spark leverages in-memory processing and parallel computing to efficiently handle big data. It can distribute data across a cluster of machines and perform computations in parallel.
Q: What programming languages can be used with Apache Spark?
A: Apache Spark supports multiple programming languages including Python, Scala, and Java.
Q: What are some commonly used operations in Apache Spark?
A: Some commonly used operations in Apache Spark include transformations (e.g., map, filter) and actions (e.g., count, collect). These operations allow data manipulation and analysis.
Q: Is Apache Spark suitable for real-time data processing?
A: Yes, Apache Spark can handle real-time data processing through its ability to process data in near real-time and support streaming data sources like Kafka.
Q: Can Apache Spark be used for machine learning?
A: Yes, Apache Spark has a machine learning library called MLlib that provides various machine learning algorithms and tools.
Q: Is Apache Spark only suitable for big data?
A: No, while Apache Spark is commonly used for big data processing, it can also be used for smaller-scale data processing tasks.